Picture this scenario. Your transcription vendor delivers an expert call transcript and reports 96% word-level accuracy. Sounds solid. But buried in the 4% it got wrong: the ASR rendered “Ericsson” as “Erickson,” turned “29% market share” into “9% market share,” and tagged the speaker as “Unknown Analyst” instead of the named equity research analyst at UBS who made the statement.
A sentiment model downstream ingested the transcript, flagged the call as bearish, and surfaced it to a portfolio manager who never listened to the original audio. Every word around those errors was transcribed perfectly. The filler words, the ums, the pleasantries. All correct. The tokens that actually mattered for investment analysis? Wrong.
This is the core problem with aggregate accuracy metrics in financial transcription. A 96% word error rate doesn’t tell you which 4% failed. And in entity-dense financial audio (expert calls, earnings presentations, due diligence interviews) the failure modes aren’t random.
They cluster around the exact tokens your clients depend on: company names, numerical figures, speaker identities, and domain-specific terminology. Research on the Earnings-21 benchmark, a 39-hour corpus of real earnings calls, confirms this pattern. ASR systems that perform well on general benchmarks degrade significantly when measured on named entity recognition in financial speech.
The problem isn’t that today’s ASR models are bad. They’re remarkably capable on general audio. The problem is that the transcription vendor ecosystem hasn’t built production workflows designed to catch the specific, high-cost errors these models make on financial content. Accent variability across APAC-originating calls, hallucinated tokens generated during silence or disfluency, and numerical precision failures all persist at rates that matter for downstream analysis.
Human-in-the-loop AI isn’t a concession to the model’s limitations. It’s the engineering response: a workflow architecture that targets human review precisely where the model can’t be trusted. What follows is a technically grounded framework for understanding why that architecture matters, how NIST’s AI 600-1 risk framework supports it, and what to ask your transcription vendors when they claim “human review” but mean something far less rigorous.
Why Aggregate ASR Word Error Rate Misleads in Financial Transcription
Word Error Rate (WER) is the default metric for evaluating speech-to-text systems, and for good reason. It’s straightforward, standardized, and gives you a single number to compare vendors against each other. But for expert networks and financial data platforms processing entity-dense audio, WER alone creates a dangerous blind spot. It tells you how much the model got wrong. It doesn’t tell you what it got wrong.
That distinction matters more in financial transcription than in almost any other domain.
How Word Error Rate Is Calculated and What It Actually Measures
WER is computed by aligning a system’s output against a verified reference transcript, then counting three types of errors: substitutions (wrong word), deletions (missing word), and insertions (extra word). You divide the total error count by the number of words in the reference. A transcript with 5 errors in 100 words scores a 5% WER, or equivalently, 95% word-level accuracy.
It’s a useful general metric. It captures the overall fidelity of a transcription system across a full document. For podcast transcription, meeting notes, or voice assistant queries, WER provides a reasonable proxy for quality. The problem isn’t that WER is flawed. It’s that WER is flat. Every token carries equal weight in the calculation. A substitution on the word “the” counts the same as a substitution on “Ericsson.” A deleted “um” penalizes the score identically to a deleted “$2.4 billion.”
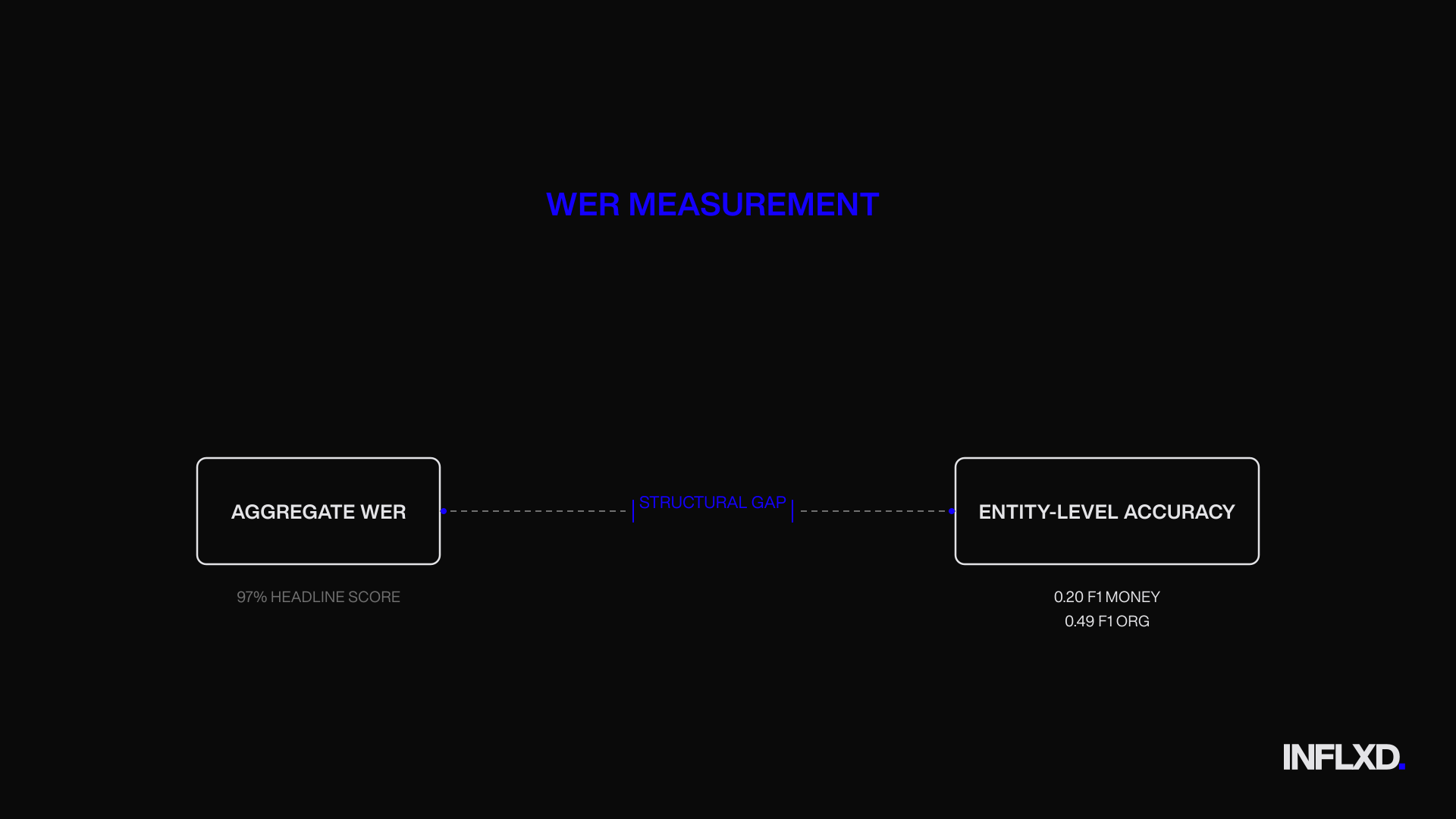
In general-purpose audio, that’s a reasonable tradeoff. In financial audio, it’s not. The tokens that carry analytical weight (company names, monetary values, percentages, speaker identities, ticker symbols) represent a small fraction of total words but an outsized share of downstream value. A transcript can score 97% on aggregate WER while mangling the specific data points an analyst, portfolio manager, or compliance officer needs to act on.
Entity-Level Accuracy: Where Financial Transcription Errors Concentrate
ASR models are trained on massive, general-purpose corpora. They’re optimized to minimize overall error rates across the distribution of language they’ve seen. That optimization works beautifully for high-frequency vocabulary. Common English words, standard phrases, and predictable sentence structures get transcribed with near-perfect accuracy.
Financial entities sit at the opposite end of the distribution. Company names are often phonetically ambiguous (is it “Synopsys” or “synopsis”?). Monetary figures require precise digit-level recognition. Speaker names, especially non-Western names common in global expert calls, don’t appear frequently enough in training data to build robust acoustic models. The result is a predictable pattern: errors concentrate on low-frequency, high-value tokens while the surrounding connective tissue (articles, prepositions, filler words) is transcribed correctly.
This creates a specific problem for the transcription vendors serving expert networks and financial data platforms. A vendor can truthfully report strong aggregate accuracy while delivering transcripts where the entities most critical to financial analysis are unreliable. Heads of Product and Data at these firms need entity-level metrics, not headline WER, to evaluate whether a vendor’s output actually meets the quality bar their clients demand.
The Earnings-21 Benchmark and NER F1 Scores for Financial Audio
The most rigorous academic evidence for this pattern comes from the Earnings-21 benchmark, developed by Del Rio et al. It’s a 39-hour corpus of real earnings calls spanning nine financial sectors, purpose-built to test ASR performance on entity-dense speech. Unlike standard benchmarks (LibriSpeech, for example, which uses clean audiobook recordings), Earnings-21 reflects the conditions financial transcription vendors actually face: domain terminology, numerical density, multiple speakers, and variable audio quality.
The findings are striking. A 2023 ACL paper titled “Why Aren’t We NER Yet?” evaluated named entity recognition performance on ASR-generated transcripts of Earnings-21 audio. The NER F1 scores tell the story:
- MONEY entities: 0.20 F1
- CARDINAL (numerical) entities: 0.46 F1
- ORG (organization) entities: 0.49 F1
- PERSON entities: 0.55 F1
- Micro-average F1 across all entity types: 0.37
These aren’t marginal gaps. An F1 of 0.20 on monetary entities means the system is getting dollar figures right roughly one time in five. An F1 of 0.49 on organization names means about half of all company references are either missed or garbled. And the micro-average of 0.37 across all entity types means that, taken as a whole, the system fails on nearly two-thirds of the named entities in financial audio.
For expert network and FDP buyers evaluating transcription vendors, these numbers reframe the conversation entirely. A vendor quoting “97% accuracy” may be telling the truth at the aggregate word level while delivering transcripts where one in two company names and four in five dollar figures are wrong. That’s not a rounding error. That’s a structural gap between what general-purpose ASR models optimize for and what financial workflows actually require.
This is precisely why workflow design matters more than model accuracy in isolation. The next section examines a failure mode that WER doesn’t capture at all: hallucinated content that the model generates with high confidence, inserting words and phrases that were never spoken.
AI Transcription Hallucinations in Financial Audio: Not an Edge Case
The previous section showed how WER fails to capture which tokens an ASR model gets wrong. But there’s a failure mode that WER doesn’t capture at all, one that’s qualitatively different from a substitution or deletion. It’s hallucination: the model generating entire phrases or sentences that don’t exist in any form in the underlying audio.
This isn’t a mishearing. It’s not the model confusing “Synopsys” with “synopsis.” It’s fabricated content, inserted into the transcript with the same formatting and confidence as legitimate speech, with no signal to the reader that anything is wrong. For expert networks and financial data platforms whose clients rely on transcripts as primary source material, this represents a categorically different risk than ordinary transcription error.
What ASR Hallucination Means for Speech-to-Text Systems
In the context of large language models, “hallucination” typically refers to generating plausible but false statements. ASR hallucination is the speech-to-text equivalent: the model produces text that corresponds to nothing in the audio signal. The speaker didn’t say it. There’s no garbled version of it in the recording. The model invented it.
What makes this particularly dangerous is that hallucinated text is indistinguishable from accurate transcription on the page. There’s no confidence flag, no bracket, no italicized disclaimer. It reads as transcript. If a downstream analyst, compliance reviewer, or AI summarization pipeline consumes that transcript, the hallucinated content gets treated as something the expert actually said.
This is distinct from the entity-level accuracy problems discussed in the previous section. A substitution error (rendering “$2.4 billion” as “$2.4 million”) is bad, but it’s at least anchored to something the speaker said. A hallucination has no anchor at all. It’s net-new fabricated content.
Hallucination Rates and Non-Vocal Duration: The Careless Whisper Findings
The most rigorous study of ASR hallucination to date is “Careless Whisper: Speech-to-Text Hallucination Harms” by Koenecke et al., published at ACM FAccT 2024. The researchers evaluated OpenAI’s Whisper, a widely adopted open-source ASR model, and found that roughly 1% of transcriptions contained entirely hallucinated phrases or sentences. That might sound small until you consider the nature of the hallucinated content: 38% of those hallucinations included explicit harms, such as violence, inaccurate associations, or false statements of authority.
The study’s most important finding for financial transcription is the causal mechanism. Hallucination rates rose significantly for audio with longer shares of non-vocal duration. Speakers with aphasia (who exhibit longer pauses and more disfluencies) experienced hallucination rates of 1.7%, compared to 1.2% for the control group. The researchers ran a logistic regression that confirmed non-vocal duration as the most significant predictor of hallucination.
Critically, these hallucinations were non-deterministic. Re-running the same audio through the same model could produce different fabricated text. That means you can’t even rely on consistency as a quality check. The same audio file might produce a clean transcript on one pass and a hallucinated one on the next.
Why Expert Network Calls Are Structurally Vulnerable to ASR Hallucination
The audio characteristics that trigger hallucination in the Careless Whisper study aren’t edge cases in expert network calls. They’re defining features.
Expert interviews are full of long pauses. An industry expert thinking carefully before answering a sensitive question about competitive dynamics or regulatory exposure doesn’t rush to fill silence. There are natural gaps between a client’s question and the expert’s response. Disfluencies (false starts, self-corrections, mid-sentence pauses) are common, especially when experts are discussing complex technical material or speaking in a second language. APAC-originating calls frequently involve speakers whose speech patterns include longer hesitation intervals and code-switching between languages.
Every one of these characteristics maps directly to the non-vocal duration variable that Koenecke et al. identified as the primary hallucination trigger. Expert network audio isn’t incidentally vulnerable to this failure mode. It’s structurally vulnerable.
And here’s the compounding problem: hallucinated content doesn’t show up in standard WER measurement. WER is calculated by aligning system output against a reference transcript and counting substitutions, deletions, and insertions of existing words. But hallucinations add content that was never spoken. A transcript can score a perfectly reasonable WER while containing fabricated sentences, because the hallucinated text isn’t penalized by the alignment algorithm in the way you’d expect.
This means that transcription vendors relying solely on WER to validate output quality have no systematic mechanism for detecting hallucination. It’s a blind spot in the measurement framework itself. Catching hallucinated content requires a different protocol entirely: one that flags segments where model confidence is low relative to audio signal strength, where non-vocal gaps exceed a threshold, or where generated text doesn’t correspond to detectable speech energy in the source audio. In practice, that means human review targeted at the specific segments where hallucination risk is highest. It’s a workflow design problem, not a model tuning problem. And it’s one of the strongest arguments for building human oversight into the transcription production pipeline rather than treating it as an optional QA step after the fact.
What Human-in-the-Loop AI Actually Means for Transcription Production
The term “human-in-the-loop” gets used loosely. In machine learning research, it refers to specific paradigms: active learning, where human annotators label data the model is uncertain about; reinforcement learning from human feedback (RLHF), where human preferences shape model behavior; and supervised fine-tuning, where human corrections feed back into training. These are important concepts, but they describe how models learn, not how transcripts get produced.
For expert networks and financial data platforms evaluating transcription vendors, the ML definition isn’t particularly useful. What matters is the production workflow: how does human expertise get applied to the transcript your client actually receives? That’s where the meaningful distinctions live, and where most vendor claims fall apart under scrutiny.
HITL Transcription Defined: Beyond the ML Research Definition
In a transcription production context, human-in-the-loop AI means something specific. It’s a workflow architecture where human review is systematically directed at the segments, tokens, and passages where the model’s confidence is lowest and the consequence of error is highest. The model handles the high-volume transcription work it’s genuinely good at (common vocabulary, clear speech, predictable sentence structures). Confidence scoring identifies where it can’t be trusted. And trained human reviewers resolve those specific segments before the transcript ships.
This isn’t “AI plus a human fallback.” It’s a single integrated pipeline where the human review stage is designed in from the start, informed by the model’s own uncertainty signals. The human isn’t correcting mistakes after the fact. They’re resolving the segments the system has already identified as unreliable. That’s a fundamentally different production architecture than running ASR, generating a transcript, and handing it to a proofreader.

Confidence-Based Routing: How HITL Workflows Target High-Value Tokens
Modern ASR systems don’t just output text. They produce per-token or per-segment confidence scores that reflect the model’s certainty about each word it generated. A well-designed HITL workflow uses these scores as routing signals. Low-confidence tokens get flagged for human review. High-confidence tokens pass through.
But raw confidence isn’t enough. The workflow also needs to account for token value, not just token certainty. A low-confidence score on the word “the” doesn’t warrant human attention. A low-confidence score on what the model thinks is a company name, a dollar figure, or a speaker attribution absolutely does. The most effective HITL architectures layer confidence scoring with entity classification, so that entity-dense segments (the exact zones where the Earnings-21 research shows ASR accuracy degrades most severely) receive prioritized human review.
This is where the connection to the previous sections becomes concrete. The NER F1 scores from the “Why Aren’t We NER Yet?” analysis (0.20 on monetary entities, 0.49 on organization names) aren’t just diagnostic data points. They’re the empirical basis for routing decisions. If the model fails on roughly four out of five dollar figures in financial audio, then every monetary entity the model flags at low confidence should be routed to a human reviewer. The same logic applies to the hallucination risk zones identified in the Careless Whisper research: segments following extended non-vocal duration, where the model is most likely to fabricate content, should be systematically flagged for human verification.
The Difference Between Spot-Checking and Systematic Human Review
Here’s where vendor evaluation gets tricky. Many transcription providers describe their process as “human-reviewed” or even “human-in-the-loop.” But the term covers an enormous range of actual practice.
At one end: a proofreader skims the finished transcript for obvious errors. They’re reading text, not listening to audio. They’ll catch a misspelling but won’t catch a plausible-sounding hallucination or a confidently rendered wrong number. At the other end: random spot-checks on 2% of output, applied uniformly with no connection to model confidence or entity density.
Neither of these is HITL in any meaningful sense. Both treat human review as a post-hoc quality check rather than a designed production stage. The proofreader doesn’t know which segments the model struggled with. The spot-checker isn’t targeting the zones where errors concentrate. Both approaches leave the highest-risk tokens (the ones the previous sections documented as systematically unreliable) to the same random chance of being reviewed as a correctly transcribed filler word.
Systematic human review, by contrast, is confidence-driven and entity-aware. It doesn’t review everything (that would eliminate the efficiency gains of ASR). It doesn’t review randomly (that wastes human attention on segments the model already handles well). It reviews the segments where the model’s own signals indicate uncertainty, weighted by the analytical importance of the tokens involved. That’s the workflow design that turns human-in-the-loop from a marketing label into a quality architecture.
NIST AI 600-1 and the Case for Structured Human Oversight in AI Transcription
The previous sections built the empirical case: aggregate WER masks entity-level failures, hallucinations inject fabricated content with no visible signal, and confidence-based human review is the engineering response. But empirical arguments alone don’t move procurement committees. What moves procurement committees is institutional authority. That’s where NIST AI 600-1 enters the picture.
Published in July 2024, NIST AI 600-1 (the “Artificial Intelligence Risk Management Framework: Generative AI Profile”) isn’t an obscure academic paper or a think-tank white paper. It’s the federal government’s official risk management profile for generative AI systems, developed as a companion to the broader AI Risk Management Framework. Regulators reference it. Federal procurement teams cite it. And its risk taxonomy maps with striking precision onto the failure modes that financial transcription workflows face every day.
For expert networks and financial data platforms, this document provides something valuable: a standards-backed vocabulary for evaluating whether a transcription vendor’s quality architecture is real or performative.
Confabulation and Human-AI Configuration as Top-Tier GAI Risks
NIST AI 600-1 organizes generative AI risks into twelve categories. Two are directly relevant to financial transcription.
The first is confabulation, NIST’s preferred term for what the AI research community calls hallucination. The framework defines it as “the production of confidently stated but erroneous or false content by which users may be misled or deceived.” NIST flags confabulation risk as especially acute for “applications involving consequential decision making” and for “domains which require highly contextual and/or domain expertise.”
Financial transcription satisfies both criteria. Expert call transcripts feed directly into investment decisions, compliance reviews, and AI-driven analytics pipelines. The domain requires specialized vocabulary (entity names, financial instruments, regulatory terminology) that general-purpose models haven’t been optimized for. When the Careless Whisper research found that roughly 1% of Whisper transcriptions contained entirely fabricated content, and that 38% of those hallucinations included explicit harms, it was documenting exactly the confabulation risk NIST describes. The framework doesn’t treat this as a theoretical concern. It treats it as a risk that demands specific, documented mitigation.
The second relevant category is Human-AI Configuration. NIST warns explicitly about automation bias (excessive deference to automated system outputs), over-reliance on GAI-generated content, and the need for human oversight proportional to the consequence of errors. This isn’t a vague recommendation. The framework includes specific action items:
- GV-3.2-001: Oversight mechanisms should be proportional to identified risks. Higher-consequence outputs require more rigorous human review.
- MG-3.2-008: Human moderation should be applied in settings where AI models are known to perform poorly. (The Earnings-21 NER F1 scores of 0.20 on monetary entities and 0.49 on organization names establish exactly which settings those are in financial transcription.)
- MS-2.5-002: Organizations should document the extent to which human domain knowledge contributes to improving system performance.
These aren’t suggestions for future consideration. They’re governance actions that procurement and risk teams can reference today.
How NIST Guidance Applies to Financial Transcription Workflows
The practical value of NIST AI 600-1 for expert network and FDP buyers isn’t theoretical. It’s procurement-ready.
When a transcription vendor claims “human-in-the-loop,” buyers can now ask whether the vendor’s HITL architecture specifically addresses confabulation risk. Does the workflow flag segments with high hallucination probability (extended non-vocal duration, low-confidence output following silence) for mandatory human verification? Or does “human review” mean a proofreader reading text without reference to model confidence signals?
Buyers can ask whether human review is proportional to consequence, as GV-3.2-001 requires. A vendor that applies the same random 2% spot-check to filler words and monetary entities isn’t meeting that standard. A vendor that routes entity-dense, low-confidence segments to domain-trained reviewers is.
And buyers can ask whether the vendor documents how human domain expertise improves output quality, per MS-2.5-002. That means more than claiming “our team reviews transcripts.” It means demonstrating that reviewers have financial domain training, that their corrections feed back into confidence calibration, and that the process is auditable.
NIST AI 600-1 doesn’t mandate a specific workflow. What it does is give sophisticated buyers (the kind of organizations that expert networks and financial data platforms serve) a framework for distinguishing between vendors who’ve engineered structured human oversight and vendors who’ve added a marketing label. That distinction, as the next section will show, becomes even more critical when the audio involves APAC-accented and multilingual speech.
Why APAC-Accented and Multilingual Audio Degrades ASR Accuracy
The previous section established that NIST AI 600-1 explicitly identifies “performance disparities between sub-groups or languages” as a harmful bias risk in generative AI systems. That’s not an abstract concern for expert networks and financial data platforms. It’s a description of their daily production reality.
A substantial share of expert network call volume originates from APAC-based specialists, European executives speaking English as a second language, and multilingual conversations where speakers shift between languages mid-sentence. These calls often carry the highest analytical value for institutional investors. A semiconductor supply chain expert based in Taipei, a pharmaceutical regulatory specialist in Seoul, a former telco executive in Mumbai: these are precisely the voices that buyside clients pay to access. And they’re precisely the voices that generic ASR models handle worst.
Performance Disparities Across Speaker Demographics in ASR Systems
The research base here is well established. ASR systems trained predominantly on native North American and British English speech exhibit significant WER increases when processing accented speakers, non-native English speakers, and speakers with disfluencies. NIST’s own technical work on speech recognition evaluation has documented these disparities across multiple system generations.
The root cause is straightforward. Commercial ASR models learn acoustic patterns from their training data. If that data skews heavily toward native English speakers (and it does, for most large-scale models), the model builds weaker representations for phonetic patterns common in Mandarin-accented English, Hindi-accented English, Japanese-accented English, or any of the dozens of accent profiles that appear regularly in expert network calls. The model isn’t “biased” in a political sense. It’s undertrained on the acoustic distributions it encounters in global financial audio.
For transcription vendors serving expert networks, this creates a compounding problem. The entity-level accuracy gaps documented in the Earnings-21 research (0.49 F1 on organization names, 0.20 F1 on monetary entities) were measured on predominantly native-English earnings calls. When you layer accent-driven WER degradation on top of already-poor entity recognition, the effective accuracy on APAC-originating expert calls drops further still. The tokens that matter most (company names rendered through non-native phonetics, numerical figures spoken with unfamiliar prosody) sit at the intersection of two failure modes simultaneously.

Code-Switching and Multilingual Expert Calls as an ASR Failure Mode
Accent is only half the problem. Expert network calls frequently involve code-switching, where a speaker shifts between English and another language within a single turn or even a single sentence. A China-based industrials expert might quote a regulation in Mandarin, then explain its market implications in English. A Japanese pharma executive might reference a drug compound by its Japanese trade name before switching back to English for the financial analysis.
Most commercial ASR models aren’t architected to handle this. They’re configured for a single target language per audio stream. When a speaker shifts languages, the model doesn’t gracefully switch recognition modes. It forces the non-target language through its English acoustic and language models, producing garbled output, dropped segments, or (connecting back to the hallucination risk from Section 2) fabricated text where the model attempts to pattern-match foreign-language speech into English words.
This isn’t an edge case that expert networks can route around. It’s core production volume. The transcription vendor ecosystem has largely failed to build models fine-tuned on accented financial speech, multilingual code-switching patterns, or the specific vocabulary of APAC markets. That’s the gap. Expert networks know their call population includes these speakers. They need vendors whose production workflows account for it.
The HITL implication is direct. For APAC-accented and multilingual audio, human review isn’t an enhancement. It’s structurally necessary because the model’s error rate on these calls is materially higher than on standard North American English. A well-designed human-in-the-loop workflow recognizes this and routes accented or multilingual segments to reviewers with appropriate language expertise, not generalist proofreaders reading English text, but reviewers who can listen to the source audio and resolve what the model couldn’t. That’s the difference between a workflow that acknowledges demographic performance disparities and one that pretends they don’t exist.
How to Evaluate HITL Transcription Vendors: Five Procurement-Ready Questions
The previous sections laid out the structural case: aggregate WER masks entity-level failures, hallucinations inject fabricated content, NIST AI 600-1 provides a governance framework for human oversight, and APAC-accented audio compounds every failure mode. That’s the analysis. This section translates it into action.
If you’re a Head of Product, Head of Data, or procurement lead evaluating transcription vendors who claim human-in-the-loop capabilities, these five questions will separate vendors with genuine HITL architecture from those using the term as a marketing label. A vendor with a real confidence-routed human review workflow can answer each one with specifics. A vendor doing post-hoc spot-checks won’t get past the first.
Question 1: What Percentage of Tokens Receive Human Review, and How Are Low-Confidence Segments Routed?
This is the foundational question. Ask the vendor to describe their confidence scoring methodology and the routing logic that determines which segments go to human reviewers. You’re looking for specifics: What confidence threshold triggers human review? Is routing based on per-token scores, per-segment scores, or both? What percentage of total output passes through human hands on a typical financial call?
A vendor with a real HITL workflow will have concrete answers. They’ll describe confidence thresholds, explain how those thresholds were calibrated, and give you a range for human review coverage. A vendor doing random quality checks won’t have this infrastructure. They’ll default to vague language about “quality assurance processes” or “editorial review” without connecting it to model-level confidence signals.
Question 2: What Is Your Entity-Level Accuracy on Financial NER Categories?
If a vendor can only report aggregate WER, they aren’t measuring what matters for financial transcription. Ask specifically for accuracy metrics on the NER categories that drive analytical value: ORG (organization names), MONEY (monetary figures), PERSON (speaker identities), and CARDINAL (numerical values).
The Earnings-21 research established that ASR systems score as low as 0.20 F1 on monetary entities and 0.49 F1 on organization names in financial audio. These are the benchmarks your vendor should be measuring against. If they can’t produce entity-level metrics on financial audio (not clean-room test sets, but production audio representative of expert network calls) that’s a signal their quality measurement framework isn’t built for your use case.
Question 3: What Is Your Hallucination Detection and Mitigation Protocol?
This question tests whether the vendor treats confabulation as a distinct risk category or lumps it in with general transcription error. Ask them to describe how they detect fabricated content in ASR output. Do they run multiple inference passes and compare outputs for consistency? Do they flag segments following extended non-vocal duration, where the Careless Whisper research identified hallucination risk as highest? Do they have specific checks for segments where generated text doesn’t correspond to detectable speech energy in the source audio?
NIST AI 600-1 identifies confabulation as a top-tier generative AI risk requiring documented mitigation. A vendor who can’t describe a specific hallucination detection protocol is operating without safeguards against a failure mode that produces fabricated content indistinguishable from accurate transcript.
Question 4: How Do You Handle APAC-Accented Speakers and Multilingual Code-Switching?
Ask for specific workflow differences when the audio involves non-native English speakers, APAC-accented speech, or multilingual segments. You’re looking for evidence that the vendor has built distinct handling for these calls: dedicated models fine-tuned on accented financial speech, reviewers with relevant language expertise, or adjusted confidence thresholds that route more of the output to human review.
If the answer is “our model handles all accents,” that’s a red flag. The research base is clear that ASR performance degrades significantly on accented and multilingual audio. A vendor claiming uniform performance across speaker demographics either hasn’t measured it or isn’t being transparent about the results.
Question 5: Can You Document Your HITL Architecture Against NIST AI 600-1 Suggested Actions?
This question tests whether the vendor has any awareness of the emerging standards landscape for generative AI oversight. Ask them to map their human review workflow against NIST AI 600-1’s suggested actions for confabulation risk (GV-3.2-001 on proportional oversight, MG-3.2-008 on human moderation in known-poor-performance settings, MS-2.5-002 on documenting human domain expertise contributions).
Most vendors won’t have done this mapping. That’s fine. The question itself signals that you’re a sophisticated buyer who understands the governance framework and will hold vendors accountable to it. It also creates a concrete evaluation criterion: can the vendor demonstrate that their human oversight is proportional to consequence, targeted at known failure modes, and documented in a way that supports audit?
These five questions won’t guarantee you find the right vendor. But they’ll quickly eliminate the ones who’ve bolted a “human-reviewed” label onto an AI-only pipeline and called it HITL transcription. The vendors who can answer with specifics are the ones who’ve built the quality architecture that financial audio actually demands.
Building a Financial Transcription Quality Architecture with Human-in-the-Loop AI
The argument across this piece reduces to a single structural claim: the transcription vendor ecosystem has optimized for speed and cost, not for the entity-level accuracy and hallucination resilience that expert networks and financial data platforms require. The gap isn’t in ASR model quality. Models have improved dramatically. The gap is in workflow design.
That distinction matters because it reframes the procurement decision entirely. Transcription isn’t a commodity line item. For firms whose products depend on transcript quality (expert networks delivering client-ready content, financial data platforms feeding transcripts into analytics engines and AI models), it’s a data infrastructure decision. The quality of the transcript determines the ceiling for every downstream process: sentiment analysis, entity extraction, compliance review, summarization, and the investment decisions those outputs inform.
From Vendor Selection to Quality Architecture: A Framework for Expert Networks
The five procurement questions in the previous section give buyers a concrete evaluation tool. But the deeper shift is in how organizations think about the category itself.
A vendor selection mindset asks: “Who can transcribe our calls fastest and cheapest?” A quality architecture mindset asks: “What production workflow ensures the entities, figures, and attributions in our transcripts are reliable enough for our clients to act on?” Those are fundamentally different questions, and they lead to fundamentally different vendor relationships.
Human-in-the-loop AI is the architectural response to that second question. It uses the model for what it does well: high-volume first-pass transcription at speed, with strong performance on common vocabulary and predictable speech. And it directs human expertise where it’s structurally necessary: low-confidence tokens, entity-dense segments, accented audio, and hallucination-prone passages following extended silence. The Earnings-21 NER F1 scores (0.20 on monetary entities, 0.49 on organization names) and the Careless Whisper hallucination findings aren’t just research data points. They’re the empirical foundation for routing decisions in a well-designed HITL workflow.
Expert networks and financial data platforms already understand this intuitively. They know their audio is harder than a podcast or a corporate meeting. They know APAC-originating calls carry higher transcription risk. They know their clients won’t tolerate fabricated content in a transcript attributed to a named expert. What they’ve lacked isn’t awareness. It’s a vendor ecosystem that builds production workflows around these realities instead of papering over them with headline WER.
Where INFLXD Fits: Structured HITL for Financial Audio at Scale
INFLXD builds structured human-in-the-loop workflows specifically for expert network and financial data platform audio, combining ASR with multi-stage human review by finance-trained editors, confidence-based routing, and entity-level quality measurement. It’s the operationalization of the principles described throughout this piece. Not a claim of perfection, but a deliberate quality architecture designed for the domain.
As NIST AI 600-1 matures and institutional buyers grow more sophisticated about generative AI risk, the vendors who can document their HITL architecture and demonstrate entity-level accuracy on financial audio will win. The ones relying on headline WER and marketing claims won’t.
The Case for Human-in-the-Loop AI in Financial Transcription
The model isn’t the problem. The workflow is.
ASR systems have gotten remarkably good at transcribing conversational English. But “remarkably good” still means NER F1 scores as low as 0.20 for monetary entities and 0.49 for organization names on financial audio. It still means hallucination rates that climb with every pause, every accented speaker, every stretch of silence that’s routine in expert network calls. And it still means that the single number your vendor reports (aggregate WER) tells you almost nothing about whether the tokens your analysts actually depend on came through correctly.
This isn’t a case for abandoning AI. It’s a case for designing around its known failure modes. That’s what human-in-the-loop architecture does. Not proofreading. Not random QA sampling. Structured, confidence-driven routing that puts trained human reviewers on the exact segments where the model can’t be trusted: entity-dense passages, numerical claims, low-confidence tokens, and accented audio that generic ASR models weren’t built for.
NIST AI 600-1 gives you the governance framework. The five procurement questions in this piece give you the vendor evaluation toolkit. What’s left is measurement.
See Where Your Transcripts Actually Stand
INFLXD runs transcript quality benchmarking for expert networks and financial data platforms. Not headline WER. Entity-level accuracy across financial NER categories (ORG, MONEY, PERSON, GPE), hallucination detection rates, and APAC-accent performance breakdowns. You’ll see exactly where your current vendor’s output falls short of what your clients expect, with specific error examples from your own audio.
If you’re evaluating transcription quality or building the case internally for a higher standard, request a transcript quality benchmark from INFLXD and get data you can act on.