A transcript from a 45-minute expert call on specialty chemical pricing lands on an analyst’s desk. The speaker labels are swapped on three critical turns, attributing the expert’s proprietary margin commentary to the interviewer. The word error rate? 96%.
By every metric the transcription vendor reports, this is a successful delivery. By every commercial metric that matters to the expert network and its clients, the transcript is worthless.
A buyside analyst can’t cite margin insight that’s attributed to their own firm’s associate. A compliance team can’t review MNPI exposure when they can’t tell who said what.
This is the core problem with how expert network transcription gets evaluated today. The vendor ecosystem serving this market was built for earnings calls, podcasts, legal depositions, and media content. Those are controlled audio environments with professional recording setups, predictable speaker counts, and terminology that generic ASR models handle reasonably well. Expert calls are none of those things. They’re conducted over mobile phones from factory floors, hotel rooms, and moving vehicles. They feature accent diversity that spans continents within a single engagement. They involve rapid, unstructured Q&A where speakers interrupt each other and turns last fewer than five seconds. And they carry compliance obligations (MNPI handling, recording consent, data residency) that don’t exist in any other transcription category.
The result is a fundamental mismatch. Expert networks are procuring transcription from vendors whose accuracy benchmarks, speaker diarisation models, and compliance architectures weren’t designed for the audio they’re processing.
This piece breaks down why that mismatch exists and what to do about it. It covers the specific acoustic and linguistic properties that make expert calls one of the hardest audio types to transcribe accurately. It goes deep on speaker diarisation: how embedding models work, why clustering fails on short turns, and what human-in-the-loop review actually needs to catch. It treats MNPI compliance not as a sidebar but as an architectural requirement that shapes every decision from editor vetting to data residency. And it closes with a procurement framework you can hand directly to your vendor evaluation team. One that measures what actually predicts real-world transcript performance, not what’s easiest for a vendor to report.
Why Expert Call Transcription Is a Distinct Category from Financial Transcription
The transcription vendor ecosystem has spent a decade optimizing for a specific kind of financial audio. Earnings calls. Investor presentations. Conference keynotes. These are controlled environments with studio-grade recording infrastructure, pre-identified speakers reading prepared remarks, and terminology that falls within a well-defined vocabulary distribution. Generic ASR models perform reasonably well on this audio because it’s exactly what they were trained on.
Expert call transcription is a structurally different problem. Not marginally harder. Categorically different. The acoustic conditions, speaker profiles, vocabulary domains, and compliance requirements share almost nothing with the audio types that most transcription vendors have optimized their pipelines around.
Expert Call Audio vs. Earnings Call Audio: Where Generic ASR Breaks Down
Earnings calls are, from a transcription standpoint, cooperative audio. A CFO speaks into a professional microphone in a quiet conference room. They use terminology that recurs across thousands of other earnings calls in the same sector. Speaker turns are long and orderly. The call follows a predictable structure: prepared remarks, then moderated Q&A with identified analysts. Most ASR models can lean on language model priors to fill acoustic gaps because the next word is statistically predictable.
Expert calls invert nearly every one of those conditions. Participants dial in from mobile phones, laptops without external microphones, cars, and factory floors. Background noise is unpredictable and variable. Speaker turns during rapid Q&A often last fewer than five seconds, which compresses the acoustic signal available for both recognition and speaker attribution. There are no prepared remarks. The vocabulary domain shifts based on the expert’s industry, which could be anything from semiconductor packaging to Brazilian agricultural logistics to Phase III oncology trial design.
This isn’t a tuning problem that generic ASR vendors can solve by adjusting a confidence threshold. The acoustic model is receiving lower-quality input. The language model has weaker priors because the vocabulary distribution is far wider and less predictable. And the speaker diarisation model (which we’ll cover in depth in Section 3) is working with shorter utterances and more frequent turn-taking, both of which degrade clustering accuracy. The failures compound. A misrecognized technical term in a short turn that’s also misattributed to the wrong speaker doesn’t produce one error. It produces a cascade that undermines the transcript’s usability.

Accent Diversity and Code-Switching in Expert Interview Transcription
Expert networks operate globally. A single firm might run calls in the same week with a semiconductor engineer in Hsinchu, a logistics executive in São Paulo, a former regulator in Brussels, and a supply chain director in Lagos. The accent diversity across an expert network’s call volume is orders of magnitude wider than what any earnings call corpus contains.
Generic ASR models trained primarily on North American and British English handle this poorly. Phoneme mapping degrades when the model encounters unfamiliar accent patterns, and the error rate climbs fastest on the domain-specific terms that carry the most analytical value. The expert’s pronunciation of a proprietary process name or a regional regulatory framework is precisely where the model is least equipped to compensate.
Code-switching compounds the problem further. Many expert calls involve participants who transition between languages mid-sentence, particularly in markets where business conversations naturally blend English with Mandarin, Portuguese, Hindi, or other languages. Most transcription vendors can’t handle this at all. They either force a single-language model onto the entire call (producing garbled output during non-English segments) or require the expert network to route multilingual calls to a separate vendor with different turnaround times and quality standards. Neither option scales.
The Commercial Value Chain: How Transcript Quality Impacts Expert Network Revenue
Here’s what separates expert network transcription from nearly every other transcription use case. The transcript isn’t an internal record. It’s a product asset.
Expert networks monetize their transcript libraries directly, whether through platform access models, per-transcript pricing, or bundled subscriptions. When a buyside analyst searches a transcript library for expert commentary on, say, NAND flash pricing trends, the quality of that transcript determines whether the platform delivers value or frustration. A transcript with misrecognized terminology, swapped speaker labels, or garbled multilingual segments doesn’t just reflect poorly on the transcription vendor. It degrades the expert network’s core product.
This commercial reality is why expert networks deserve a transcription vendor ecosystem purpose-built for their use case. They’re sophisticated buyers with exacting quality requirements, and they’ve been underserved by vendors whose models, workflows, and quality benchmarks were designed for a fundamentally different audio type. The gap isn’t in what expert networks demand. It’s in what the existing vendor ecosystem was built to deliver.
That gap spans multiple dimensions, and word error rate captures only the most superficial of them. The next section breaks down the accuracy dimensions that actually predict whether a transcript is commercially usable.
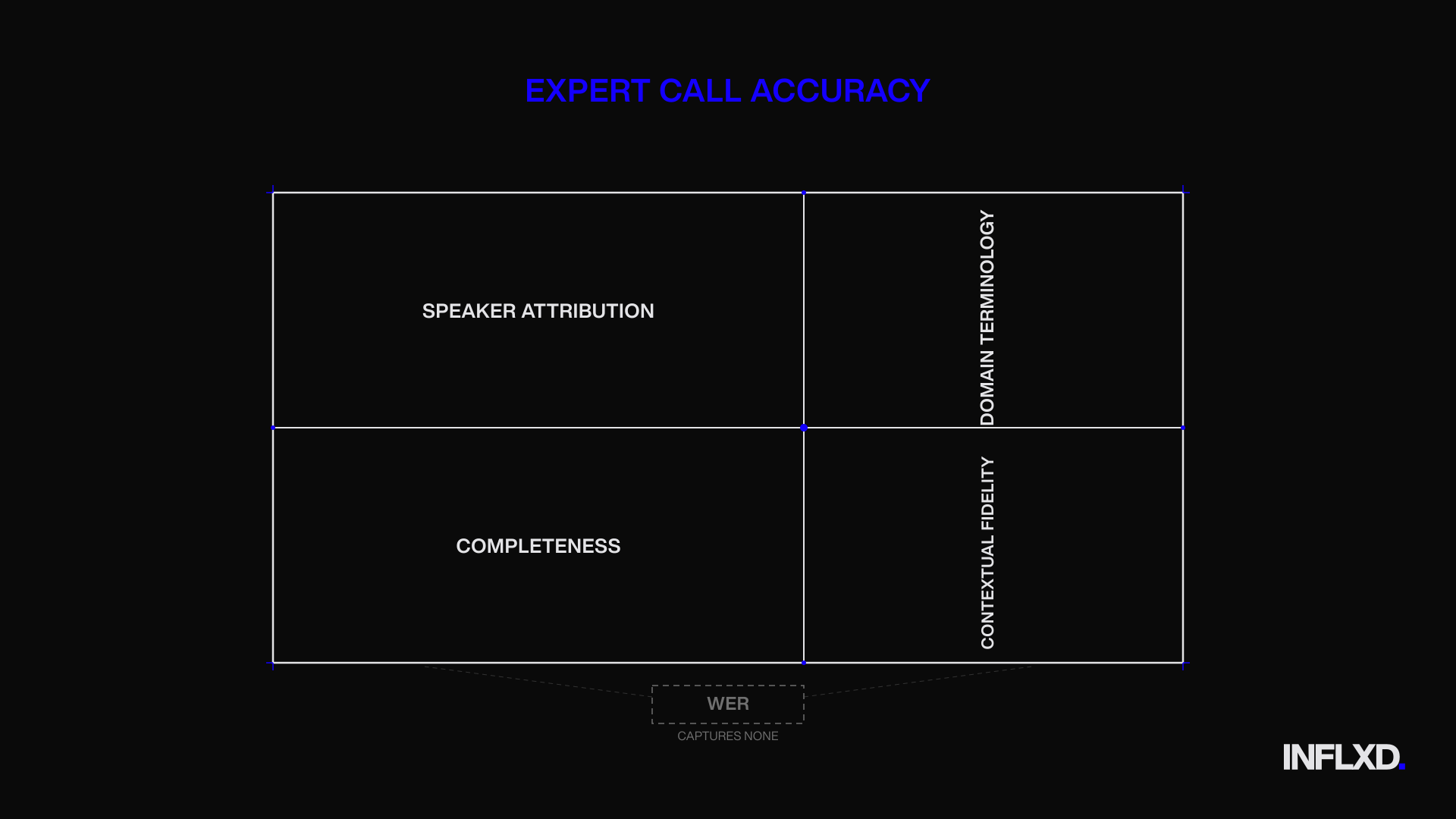
Beyond Word Error Rate: The Accuracy Dimensions That Define Expert Network Transcript Quality
Word error rate has become the default metric for evaluating transcription vendors. It’s easy to calculate, easy to compare across providers, and easy to put in an RFP scoring matrix. It’s also, for expert call transcription, the least meaningful measure of whether a transcript is commercially usable.
WER treats every word as equal. A misrecognized filler word (“um” rendered as “uh”) counts the same as a misrecognized company name, a garbled financial figure, or a speaker label swap that attributes proprietary insight to the wrong participant. A transcript can score 96% on WER and still be unusable for the analyst, the compliance team, and the platform’s search index. The 4% that’s wrong determines everything.
This isn’t a framing problem. It’s a measurement problem. And it persists because most transcription vendors built their quality reporting around audio types where WER is a reasonable proxy for usability. On earnings calls with predictable vocabulary and pre-identified speakers, a low WER genuinely correlates with a good transcript. On expert calls, that correlation breaks down.
Why Word Error Rate Is the Least Important Accuracy Metric for Expert Calls
The fundamental issue is that WER is unweighted. It doesn’t distinguish between high-value and low-value tokens in the transcript. For expert network clients, the tokens that carry the most analytical and commercial value are precisely the ones most likely to be misrecognized: proper nouns (company names, product names, regulatory frameworks), financial figures, and domain-specific terminology that falls outside generic language model priors.
Inflxd’s benchmarking methodology addresses this directly through a weight-adjusted WER model. This approach applies greater penalty to errors on proper nouns, financial figures, and industry-specific terminology than to errors on common vocabulary. The result is a quality score that correlates far more closely with real-world transcript usability than raw WER does. When a vendor reports 95% WER, the question isn’t whether that number is accurate. It’s whether that number tells you anything about the transcript’s fitness for your clients’ workflows.
Speaker Attribution Accuracy in Expert Call Transcription
Speaker attribution is arguably the single highest-stakes accuracy dimension for expert networks. If an expert’s proprietary commentary gets labeled as the interviewer’s words (or vice versa), the transcript fails at its most basic function. Buyside analysts can’t cite insight that’s attributed to their own firm’s associate. Compliance teams can’t assess MNPI exposure without knowing who disclosed what.
Speaker diarisation (covered in technical depth in Section 3) is where generic transcription vendors struggle most on expert calls. But the point here isn’t about the technical mechanism. It’s about the commercial consequence. Speaker attribution errors don’t show up in WER at all. A transcript where every word is correctly recognized but three turns are assigned to the wrong speaker will score perfectly on WER. It will also be useless.
Any vendor evaluation that doesn’t measure speaker attribution accuracy as a standalone metric is missing the dimension most likely to determine whether the transcript delivers value or creates risk.
Domain Terminology Handling Across Sectors
Expert networks run calls across dozens of industries in any given week. The vocabulary domain shifts from semiconductor fabrication to specialty pharma to agricultural commodity logistics, sometimes within the same client engagement. Generic ASR models trained on broad corpora handle common business English well enough. They fall apart on the terms that matter most.
Consider what happens when a model encounters a proprietary process name it’s never seen, a regional regulatory acronym, or a chemical compound discussed in the context of pricing dynamics. These aren’t edge cases. They’re the core content of expert calls. And when the model substitutes a phonetically similar common word for a domain-specific term, the error doesn’t just reduce accuracy. It changes meaning.
This is where the vendor ecosystem’s limitations are most visible. Most transcription providers don’t maintain sector-specific language models or terminology libraries tuned to the breadth of domains that expert networks cover. The result is that domain term accuracy (the metric that most directly predicts whether an analyst can trust the transcript) gets treated as a residual of general model performance rather than as a first-class optimization target.
Completeness and Contextual Fidelity in Expert Interview Transcription
Two final dimensions round out the accuracy picture. The first is completeness. Expert calls contain brief but critical exchanges: one-word confirmations, clarifying follow-ups, hedged qualifications that change the meaning of a preceding statement. Generic transcription pipelines often drop these short utterances, particularly when they overlap with another speaker or fall below a confidence threshold. The transcript reads cleanly, but it’s missing the connective tissue that gives the conversation its analytical value.
The second is contextual fidelity. This refers to errors that don’t just misrecognize a word but reverse or materially alter meaning. “Doesn’t motivate” versus “does motivate.” “We can’t sustain” versus “we can sustain.” These errors are invisible in WER reporting because the substituted word is a real word in the right syntactic position. They’re only caught through contextual review, which requires either human editors with domain awareness or post-ASR models specifically trained to flag meaning-altering substitutions.
Together, these four dimensions (speaker attribution, domain terminology, completeness, and contextual fidelity) define what transcript accuracy actually means for expert networks. WER captures none of them adequately. Procurement teams that default to WER as their primary evaluation metric aren’t making a mistake. They’re working with the only metric the vendor ecosystem has historically provided. The fix isn’t better procurement. It’s better measurement frameworks from vendors who understand what accuracy means in this specific context.
Speaker Diarisation in Expert Calls: Why Speaker Labels in Transcription Fail and How to Fix Them
Speaker attribution errors don’t register in word error rate reporting. They don’t show up in most vendor quality dashboards. But they’re the single fastest way to destroy the commercial value of an expert call transcript. The previous section established that speaker attribution is a standalone accuracy dimension. This section explains the technical mechanics of why it fails on expert calls, why those failures compound, and what it actually takes to fix them.
How Speaker Diarisation Works: Embeddings, Clustering, and Where Expert Call Audio Defeats the Model
Modern speaker diarisation operates in two stages. First, the system extracts speaker embeddings from audio segments. These are vector representations of vocal characteristics (pitch, cadence, timbre, spectral features) that encode what a speaker “sounds like” into a mathematical form the model can compare. Second, a clustering algorithm groups those embeddings, assigning segments with similar vectors to the same speaker label.
This pipeline works well under a specific set of conditions: speakers have distinct vocal profiles, turns are long enough to generate stable embeddings, audio quality is clean, and there are few speakers. Earnings calls meet all four conditions. Expert calls meet none of them.
Start with audio quality. Expert call participants dial in from mobile phones, laptops without external microphones, and noisy environments. Background noise contaminates the acoustic signal, which degrades the quality of the extracted embeddings. The vectors become noisier, and the distance between speakers in embedding space shrinks. The clustering algorithm has less separation to work with.
Then consider turn length. Rapid Q&A is the dominant conversational mode in expert calls. Turns frequently last fewer than five seconds. Short turns give the embedding extractor less acoustic data per segment, producing less stable vector representations. The clustering algorithm receives inputs that are inherently less reliable, and its confidence in speaker assignment drops accordingly.
Accent diversity introduces a third failure point. The acoustic models underlying embedding extraction are trained on specific distributions of speech. When a speaker’s accent falls outside that training distribution (as it frequently does across expert networks’ global call volumes), the model’s ability to extract discriminative embeddings degrades. Two speakers with unfamiliar accents may produce embeddings that are closer to each other than they should be, causing the clustering algorithm to merge them into a single speaker.
Overlapping speech creates a fourth problem. During cross-talk (common in unstructured Q&A), two speakers are active simultaneously. The system must either assign the overlapping segment to one speaker, split it, or drop it entirely. Most diarisation models handle this poorly, and the result is either a misattributed segment or a gap in the transcript.
Finally, code-switching (where a speaker transitions between languages mid-turn) can cause the model to treat a single speaker as two different speakers. The acoustic profile shifts enough during the language transition that the embedding extractor generates vectors in different regions of the embedding space. The clustering algorithm, seeing what looks like two distinct vocal signatures, assigns two labels to one person.
Compounding Failure Modes for Speaker Labels in Transcription of Expert Interviews
Each of these failure modes is manageable in isolation. A diarisation model can handle noisy audio if turns are long. It can handle short turns if the audio is clean and speakers are acoustically distinct. It can handle accent diversity if there’s no cross-talk.
Expert calls present all five failure modes simultaneously. And the errors compound rather than cancel. A short turn from a speaker with an unfamiliar accent, recorded on a mobile phone, during a rapid exchange where speakers briefly overlap: that’s not an edge case in expert call audio. That’s a typical segment. The embedding extractor is working with degraded input. The clustering algorithm is making low-confidence assignments. And there’s no structural feature of the audio (like a moderator introducing speakers by name, as on an earnings call) to provide a correction signal.
The compounding effect means that diarisation accuracy on expert calls can’t be predicted from performance benchmarks run on clean, controlled audio. A vendor whose diarisation model performs well on earnings calls or podcast audio may see dramatically worse performance on expert calls, not because the model is bad, but because it was never tested against audio that attacks every assumption in its pipeline at once.
Human-in-the-Loop Review as the Backstop for Speaker Attribution Accuracy
For high-stakes attribution (where misattributing an expert’s proprietary insight to the interviewer renders the transcript commercially useless), automated diarisation alone isn’t sufficient. Human-in-the-loop review is the only reliable backstop.
At Inflxd, speaker verification is a dedicated stage in the multi-pass editing pipeline. It isn’t treated as a byproduct of general transcription review. Editors with context on the call’s structure verify speaker assignments against vocal cues, conversational logic, and any available metadata. This is where errors that automated systems can’t self-correct get caught: the short turn assigned to the wrong cluster, the code-switched segment split across two speaker labels, the cross-talk segment attributed to only one participant.
The impact of this approach shows up clearly in benchmarking data. In benchmarking conducted against a major financial data provider’s transcripts, Inflxd’s speaker identification scored +3.87 points higher on a 10-point scale. That’s the single largest quality advantage across all dimensions measured. Specific examples from that benchmarking included resolving 15+ “Unknown Analyst” labels into correctly identified speakers and correcting wrongly attributed speaker names throughout the transcript.
That gap doesn’t come from a better clustering algorithm alone. It comes from treating speaker attribution as a first-class quality dimension with its own verification stage, its own error taxonomy, and its own pass/fail criteria. For expert networks whose transcript libraries serve as searchable product assets, that distinction is the difference between a transcript that delivers value and one that creates confusion.
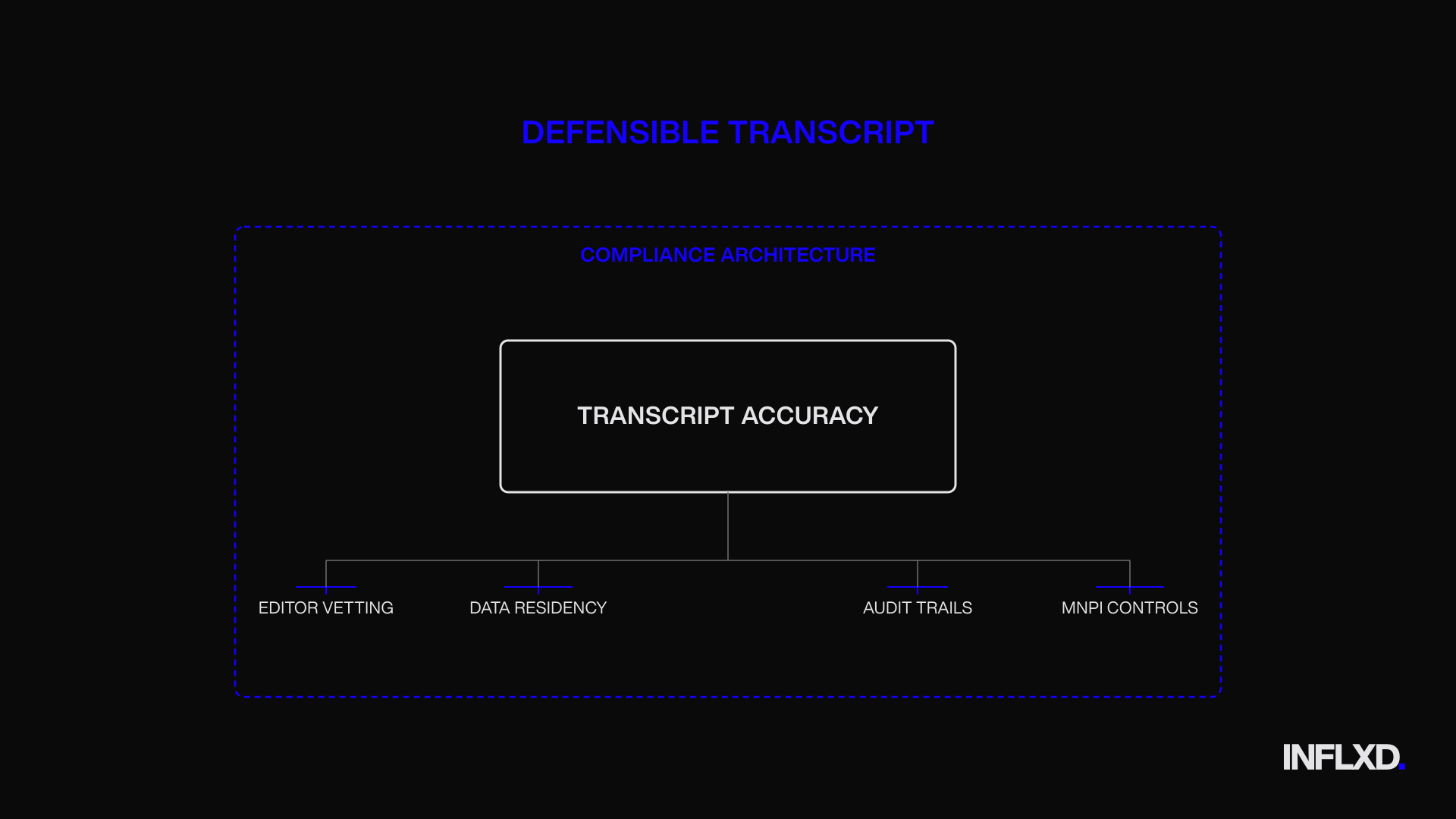
MNPI Compliance Transcription: Why Compliance Must Be Architectural, Not Bolted On
A transcript can be verbatim accurate, perfectly diarised, and delivered in under four hours. If it was produced through a workflow with no MNPI controls, no editor background checks, no data residency guarantees, and no audit trail, it’s not a compliant transcript. And for expert networks operating under regulatory scrutiny from institutional investors, it’s not a usable transcript.
This is the point most transcription vendor evaluations miss entirely. Compliance isn’t a separate concern from transcription quality. It’s a dimension of quality. The previous sections covered speaker attribution, domain terminology, completeness, and contextual fidelity. Compliance posture belongs on that same list. A transcript that fails on any of those dimensions fails commercially. A transcript that fails on compliance fails commercially and creates regulatory exposure for the expert network and its clients.
Expert networks understand this deeply. They’ve built sophisticated internal compliance programs covering call monitoring, expert screening, and client-facing audit documentation. The problem is that the transcription vendor ecosystem hasn’t kept pace. Most generic transcription providers were built for media, education, legal, or consumer use cases where material non-public information isn’t a concept. Retrofitting compliance onto a platform designed without it creates structural gaps that expert networks must then patch manually, absorbing audit risk and operational overhead that should sit with the vendor.
Recording Consent, MNPI Flagging, and Audit Trails in the Transcription Workflow
Compliance in expert call transcription isn’t a single checkbox. It’s a chain of controls that must hold at every stage of the workflow, from audio intake to final transcript delivery. Three capabilities are non-negotiable.
Recording consent verification must be integrated into the intake workflow, not handled as a separate manual step. The transcription system should confirm that consent documentation exists before processing begins. When consent verification lives outside the transcription pipeline (in a separate system, tracked in a spreadsheet, or assumed by default), the gap between the two systems becomes an audit liability.
MNPI flagging is the capability most conspicuously absent from generic transcription platforms. Expert calls routinely touch on information that could constitute material non-public information: unreleased financial results, unannounced product decisions, pending regulatory actions. Whether flagging is automated, human-assisted, or both, the transcription workflow needs to identify potentially material content before the transcript reaches the client’s compliance team. This doesn’t mean the transcription vendor makes the MNPI determination. It means the vendor surfaces candidates for review so the expert network’s compliance function can act on them efficiently rather than reading every transcript line by line.
Audit trails must document the full chain of custody. Who accessed the audio. Who edited the transcript. What changes were made, and when. Which version was delivered. Generic transcription platforms often lack granular access logging because their original use cases never required it. For expert networks whose institutional clients conduct vendor oversight reviews, an incomplete audit trail isn’t just an inconvenience. It’s a finding.
Editor Vetting and Data Residency as Compliance Infrastructure
The human editors who touch expert call audio represent one of the most significant compliance surfaces in the transcription workflow. They hear raw, unfiltered conversations between experts and buyside analysts. They hear the MNPI before anyone flags it. They hear the proprietary insight before it reaches the client.
Generic transcription vendors that rely on gig-economy freelancer pools with minimal vetting create a compliance exposure that no amount of post-hoc NDA signing can fully remediate. Compliance infrastructure for expert call transcription requires background-checked editors, enforceable NDAs executed before any audio access, and security training specific to financial information handling. This isn’t optional. It’s the baseline.
Data residency is the other structural requirement that generic platforms routinely fail to address. Institutional investors increasingly specify where audio and transcript data can be stored and processed. A transcription vendor that routes audio through servers in jurisdictions that don’t meet a client’s regulatory requirements creates a compliance problem the expert network inherits.
Inflxd’s platform architecture was designed around these requirements from the ground up. The closed-loop system operates in zero-download, containerized, stateless environments. Audio and transcript data are protected with AES-256 encryption and subject to automatic deletion after 45 days. Editors work within the platform without the ability to extract audio files. Inflxd is also developing an MNPI compliance augmentation tool designed to flag potentially material content within the transcription workflow itself. These aren’t features bolted onto a consumer platform. They’re the architectural foundation of a system purpose-built for expert network transcription.
The Cost of Compliance Gaps in Expert Network Transcription Vendors
Compliance posture has shifted from a procurement preference to a procurement requirement. Institutional investors (the expert network’s end clients) now routinely audit their vendors’ vendor chains. When a hedge fund’s compliance team asks an expert network to document its transcription vendor’s data handling practices, editor vetting protocols, and audit trail capabilities, the expert network needs answers that hold up under scrutiny.
A transcription vendor that can’t provide those answers doesn’t just create operational friction. It creates client attrition risk. Expert networks competing for institutional mandates increasingly differentiate on the robustness of their compliance infrastructure. The transcription vendor is a critical link in that chain. If it’s the weak link, the expert network bears the consequence.
This is why evaluating transcription vendors on accuracy alone (even on the multi-dimensional accuracy framework outlined in earlier sections) isn’t sufficient. Accuracy tells you whether the transcript is correct. Compliance posture tells you whether it’s defensible. For expert networks operating in today’s regulatory environment, both are required. Neither is optional.
Turnaround Reliability and Volume Surge Capacity in Expert Call Transcription
Accuracy, diarisation, and compliance posture all matter. But none of them matter if the transcript arrives late. Expert networks operate on client-driven timelines. A buyside analyst who requested a call on Tuesday morning expects the transcript before their Wednesday investment committee meeting. A four-hour SLA that slips to eight hours during earnings season isn’t a minor inconvenience. It’s a delivery failure that erodes client trust.
Most transcription vendors publish turnaround SLAs. Fewer can demonstrate that those SLAs hold under real-world volume conditions. And this is the gap that procurement teams often overlook: the difference between a stated SLA and a stress-tested one.
Why Turnaround SLAs for Expert Network Transcription Must Be Stress-Tested
Expert networks experience two types of volume spikes. The first is predictable: quarter-end surges, earnings season, annual planning cycles. The second is unpredictable: breaking sector news, unexpected M&A activity, regulatory announcements that trigger a wave of expert consultations across an entire industry vertical. Both types can push call volumes 20% or more above baseline within days.
A vendor’s SLA is only as credible as its performance during these spikes. Procurement teams should be asking for documented on-time delivery rates across a full calendar year (not a cherry-picked quarter) and specifically requesting data from peak volume periods. A vendor that maintains 99% on-time delivery at 2,000 hours per month but drops to 85% at 2,500 hours isn’t meeting the SLA. It’s meeting a conditional version of it.
Inflxd has maintained 100% on-time delivery over 12 consecutive months at volumes exceeding 4,000 hours per month, with the capacity to absorb 20% volume surges without advance notice. That’s the type of operational evidence procurement teams should demand from any vendor in this space. Not a promised SLA. A demonstrated one.
Dedicated Editorial Teams vs. Gig-Economy Freelancer Models for Financial Transcription Accuracy
The turnaround reliability gap traces directly to workforce architecture. Two models dominate the transcription vendor ecosystem, and they produce very different outcomes under pressure.
The first model relies on gig-economy freelancer pools. Editors are drawn from a large, loosely managed roster. Availability fluctuates based on individual schedules. Style guide adherence varies because editors cycle across dozens of clients. Surge capacity is theoretically available (more freelancers can be activated) but practically unreliable, because the editors who come online during a spike haven’t been trained on the expert network’s specific formatting requirements, terminology preferences, or compliance protocols. The result is that turnaround may hold during surges, but quality degrades. Or quality holds, but turnaround slips. Rarely do both survive a spike intact.
The second model uses dedicated, ringfenced editorial teams trained on a specific client’s style guide, with built-in surge capacity and daily QA scoring. This model costs more per audio minute. But when you factor in rework cycles from inconsistent freelancer output, missed deadlines during volume spikes, and the compliance risk of routing sensitive expert call audio through a loosely vetted freelancer pool, the total cost of ownership is lower.
Inflxd operates the second model exclusively. Its editorial teams are ringfenced by client, trained on client-specific style guides, and subject to a less than 1% editor acceptance rate that ensures baseline capability before any production work begins. Daily QA scoring means quality doesn’t drift over time. And because surge capacity is built into the team structure rather than sourced ad hoc from a freelancer marketplace, turnaround commitments hold even when volume spikes hit without warning.
For expert networks evaluating transcription partners, the question isn’t just “what’s your SLA?” It’s “show me your on-time rate at peak volume, your editor retention metrics, and your QA cadence.” The answers separate vendors who can promise reliability from vendors who can prove it.
A Vendor Evaluation Framework for Expert Network Transcription Procurement
The previous sections laid out what makes expert call transcription distinct, which accuracy dimensions actually matter, how speaker diarisation fails on this audio type, why compliance must be architectural, and what separates reliable turnaround from a conditional SLA. This section translates all of that into something you can hand directly to your procurement team.
Most transcription vendor evaluations default to a simple matrix: WER, turnaround time, price per minute. That framework was designed for commodity audio. It doesn’t capture the dimensions that determine whether a vendor can actually serve an expert network’s quality and compliance requirements. What follows is a weighted evaluation framework, a pilot structure, and a set of questions designed specifically for expert call transcription procurement.
Five Evaluation Dimensions for Expert Call Transcription Vendors
These five dimensions reflect the accuracy, compliance, and operational realities covered throughout this piece. The weightings are calibrated to the commercial impact each dimension has on an expert network’s product quality and risk posture.
- Speaker attribution accuracy (25%). Test on real expert call samples with diverse audio conditions: mobile phone recordings, non-native English speakers, rapid Q&A with short turns. Don’t accept results from vendor-supplied demo files. Measure how many turns are correctly attributed, how many “Unknown Speaker” labels appear, and whether the vendor can resolve speaker identities against available metadata.
- Compliance infrastructure (25%). Evaluate MNPI controls, editor vetting processes (acceptance rate, background check protocols, NDA enforcement), data residency options, encryption standards (AES-256 minimum), audit trail completeness, and relevant certifications. Request documentation, not just verbal assurances.
- Domain terminology handling (20%). Measure across multiple sectors the expert network covers. Include edge cases: biotech nomenclature (drug names, mechanism-of-action terminology), energy trading jargon, semiconductor supply chain terms, regional regulatory acronyms. Score on whether domain terms are correctly rendered, not just phonetically approximated.
- Turnaround reliability under volume spikes (15%). Don’t evaluate turnaround at steady-state volume only. Structure the pilot to include at least one simulated surge period (20%+ above baseline). Request the vendor’s documented on-time delivery rate across a full calendar year, specifically including peak volume periods.
- Security posture (15%). Assess platform architecture (closed-loop vs. open), whether editors can download or extract audio files, data retention and deletion policies, and insurance coverage. A vendor that can’t articulate its data lifecycle from intake to deletion isn’t ready for expert network audio.
How to Structure a Transcription Vendor Pilot for Expert Networks
A pilot that only tests clean, straightforward calls tells you nothing about how the vendor will perform on the audio that actually causes problems. Here’s how to structure one that does.
Submit a representative sample of real calls. Don’t cherry-pick clean audio. Include calls with heavy accents, code-switching between languages, poor mobile phone quality, and rapid speaker turns. If your call volume includes three-party calls or calls where the expert joins from a noisy environment, include those too. The pilot sample should reflect the full distribution of your audio, not the best 10%.
Evaluate the returned transcripts on the dimensions that matter. Score speaker attribution accuracy by checking every speaker turn against the original audio. Score domain terminology by flagging every sector-specific term and verifying whether it’s correctly rendered. Score completeness by checking whether short utterances, confirmations, and hedged qualifications survived the transcription process. Don’t reduce the evaluation to a single WER number.
Request the vendor’s compliance documentation for the pilot files specifically. Who accessed the audio? What’s the audit trail? Where was the data processed and stored? If the vendor can’t produce this for a pilot, they can’t produce it at scale.
Questions Procurement Teams Should Ask Transcription Vendors
These questions are designed to surface capability gaps that generic vendor presentations won’t reveal.
- What’s your speaker diarisation accuracy rate on multi-speaker calls with non-native English speakers? Can you share benchmarking data on this specific audio type?
- How do you handle code-switching between languages within a single call?
- What’s your editor vetting process? What percentage of applicants do you accept, and what background checks do you conduct before granting audio access?
- Can you demonstrate your MNPI flagging capability on a sample call?
- What’s your data retention policy? Can clients request immediate deletion, and how do you verify that deletion is complete?
- What happens to your turnaround SLA when volume spikes 20% above forecast? Can you share on-time delivery data from your last three peak periods?
- Is your platform architecture closed-loop? Can editors download or extract audio files at any point in the workflow?
Any vendor that can answer these questions with specifics and documentation is worth evaluating further. Any vendor that deflects toward generic WER benchmarks or promises to “customize” their compliance posture post-contract is telling you everything you need to know.
This framework isn’t designed to be exhaustive. It’s designed to filter out vendors whose infrastructure wasn’t built for the complexity of expert call transcription before you invest months in an integration that won’t hold up under real-world conditions.
The Future of Expert Network Transcription: From Commodity Vendor to Strategic Data Partner
Legal transcription became its own procurement category decades ago. Medical transcription followed. In both cases, the catalyst was the same: the failure modes, compliance demands, and domain vocabulary were so distinct from general transcription that generic vendors couldn’t serve the market at the quality level buyers required. Specialized vendors emerged, purpose-built standards followed, and procurement teams stopped evaluating legal transcription providers on the same scorecard they used for media or corporate audio.
Expert network transcription is following the same trajectory. The preceding sections of this piece document why: the acoustic conditions are harder, the speaker diarisation challenges are structurally different, the compliance requirements (MNPI handling, editor vetting, data residency, audit trails) don’t exist in any other transcription category, and the commercial stakes are higher because the transcript is a revenue-generating product asset, not an internal record. These aren’t incremental differences from generic financial transcription. They’re categorical ones. And they’re driving expert network transcription toward recognition as a distinct procurement category with its own evaluation criteria, its own vendor landscape, and its own quality benchmarks.
What Strategic Transcription Partnership Looks Like for Expert Networks
The difference between a commodity transcription vendor and a strategic transcription partner isn’t just quality scores. It’s architectural alignment with the expert network’s business model and regulatory reality.
A strategic partner builds technology purpose-designed for expert call audio: models tuned for accent diversity, short-turn diarisation, and cross-sector vocabulary breadth. Its compliance infrastructure isn’t retrofitted. It’s foundational, with closed-loop editor environments, AES-256 encryption, automatic data deletion policies, and MNPI flagging capabilities integrated into the production workflow. Its editorial teams are ringfenced, domain-trained, and vetted at acceptance rates (like Inflxd’s sub-1%) that reflect the sensitivity of the content they handle. Its platform connects to the expert network’s systems through API-first integration rather than manual file transfers. And its product roadmap aligns with where the expert network industry is heading: compliance augmentation tooling, moderator co-pilot capabilities, and expert credibility verification layers that extend the transcript’s value beyond raw text.
That last point matters more than it might seem. As expert networks increasingly productize their transcript libraries and as institutional investors intensify scrutiny of data provenance and compliance documentation, the gap between what generic vendors deliver and what the market requires won’t narrow. It’ll widen. The transcription vendor ecosystem wasn’t built for this use case, and incremental improvements to general-purpose platforms won’t close a structural gap.
The expert networks that treat transcription as strategic infrastructure (with vendor selection criteria calibrated to the dimensions outlined in this piece) will hold a structural advantage. Not because they’re spending more. Because they’re spending on a partner whose capabilities match the actual complexity of their audio, the actual sensitivity of their content, and the actual expectations of their institutional clients.
If you’ve read this far, you already know whether your current transcription vendor meets the bar this framework sets. Inflxd’s Transcription Pilot Scorecard provides a structured way to evaluate that gap across all five dimensions covered in Section 6. And if you’d prefer to see the difference rather than score it, we’ll run a benchmarking pilot on your real expert call samples, with your hardest audio, scored on the metrics that actually predict commercial usability. Reach out to the Inflxd team to get started.
Why Expert Network Transcription Demands a Different Vendor Model
The argument running through this piece is simple, but it has real procurement consequences. Expert network transcription isn’t a variant of financial transcription. It’s a distinct category with distinct failure modes, and evaluating vendors as if it were anything else is how quality gaps persist.
Word error rate doesn’t capture what breaks. Speaker attribution errors turn usable intelligence into liability. Compliance gaps that exist below the workflow level can’t be patched with policy documents. Turnaround commitments that collapse under volume spikes erode client trust faster than any terminology error. And generic ASR models, no matter how aggressively they’re marketed, weren’t trained on the audio conditions that define expert calls: variable recording environments, accent diversity, rapid speaker turns, domain-dense vocabulary that shifts by sector and geography.
The vendor ecosystem serving expert networks today was built for cleaner, more predictable audio types. That’s not a criticism of the networks procuring transcription. It’s a structural mismatch between what these firms need and what most providers were designed to deliver. Closing that gap requires evaluating vendors across five dimensions simultaneously: speaker attribution accuracy on real call samples, domain terminology handling, compliance infrastructure (not compliance claims), turnaround reliability under surge conditions, and security posture including editor vetting and data residency.
Expert networks that treat transcription procurement as a commodity purchasing decision will keep getting commodity results. The firms that treat it as a data quality decision will build a measurable advantage in the accuracy, attribution, and compliance posture their clients actually evaluate.
Inflxd works with expert networks and financial data platforms to measure exactly where transcription quality is falling short. If you’re evaluating your current vendor’s performance or building a shortlist for 2026, start with a transcript quality audit. Send us a sample set of real call transcripts and we’ll benchmark them across the dimensions that matter: speaker attribution, domain accuracy, compliance readiness, and turnaround consistency. No generic scores. Specific, measurable gaps you can act on.
Request a transcript quality audit →